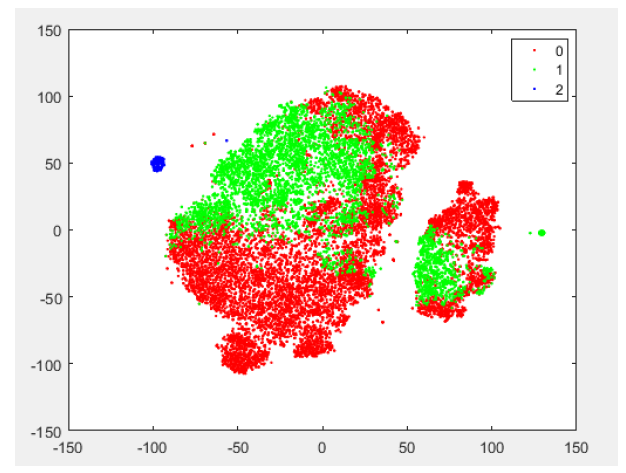
| [1] |
S.A. Mcllaith, T.C. Son, H.L. Zeng . Semantic Web Services[J]. IEEE Intelligent Systems, 2001,16(2):46-53.
|
| [2] |
张贝妮, 王军 . 数字图书馆中的检索式扩展方法研究[J]. 计算机应用研究, 2006,23(4):71-73.
|
|
Zhang B N, Wang J . Research of Query Reformulation in Digital Library[J]. Application Research of Computers, 2006,23(4):71-73.
|
| [3] |
M. Almasri, C. Berrut, J.P. Chevallet . A Comparison of Deep Learning Based Query Expansion with Pseudo-Relevance Feedback and Mutual Information[M] // Advances in Information Retrieval. Springer International Publishing, 2016.
|
| [4] |
F. Diaz, B. Mitra, N. Craswell . Query Expansion with Locally-Trained Word Embeddings[J]. 2016.
|
| [5] |
林睿 . 谷歌学术搜索的缺陷——基于检索式、专利及引用功能的抽样分析[J]. 现代情报, 2014,34(2):103-106.
|
|
Lin R . Deficiencies in the Use of Google Scholar——Analysis on the sample of Retrieval Strategy , Patents and Reference Functions[J]. Journal of Modern Information, 2014,34(2):103-106.
|
| [6] |
毛媛媛 . 基于语义扩展的中文信息检索系统设计与实现[D]. 电子科技大学, 2013.
|
|
Mao Y Y . Based on the Semantic Extension in Chinese Information Retrieval System Design and Implentation[D]. University of Electronic Science and Technology of China. 2013.
|
| [7] |
J.F. Gao, G,. Xu, J.X. Xu . Query expansion using path-constrained random walks [C]//Proceedings of the 36th International ACM SIGIR Conference on Research and Development in Information Retrieval, Dublin, Ireland, Jul 28-Aug 1,2013. New York, NY, USA:ACM. 2013: 563-572.
|
| [8] |
S. Riezler, Y. Liu . Query rewriting using monolingual statistical machine translation[J]. Computational Linguistics, 2010,36(3):569-582.
|
| [9] |
G.E. Hinton . Learning distributed representations of concepts [C]//Proceedings of the eighth annual conference of the cognitive science society. 1986,1:12.
|
| [10] |
唐明, 朱磊, 邹显春 . 基于Word2Vec的一种文档向量表示[J]. 计算机科学, 2016,43(6):214-217, 269.
|
|
Tang M, Zhu L, Zou X C . Document Vector Representation Based on Word2Vec[J]. Computer Science. 2016,43(6):214-217, 269.
|
| [11] |
T. Mikolov, K, Chen, G. Corrado , et al. Efficient estimation of word representations in vector space[J]. ar Xiv preprint ar Xiv: 1301.3781, 2013.
|
| [12] |
F. Morin, Y. Bengio . Hierarchical probalilistic neural network language model [C] //Proceedings of the international workshop on artificial intelligence and statistics. 2005,5:246-252.
|
| [13] |
R. Collobert, J. Weston, L. Bottou , et al. Natural language processing (almost) from scratch[J]. Journal of Machine Learning Research, 2011,12(Aug):2493-2537.
|
| [14] |
T. Mikolov, I. Sutskever, K. Chen , et al. Distributed representations of words and phrases and their compositionality [C]//Advances in neural information processing systems. 2013: 3111-3119.
|
| [15] |
Maaten L V D, G . Hinton Visualizing Data using t-SNE[J]. Journal of Machine Learning Research, 2017,9(2605):2579-2605.
|
| [16] |
D. Farkas . Wordsift: A tool for developing academic vocabulary in science. California[J]. Science Teachers Association California Classroom Science, 2009,21(2).
|
| [17] |
程妍 . 国外交叉学科研究现状分析——基于学术期刊的视角[J]. 学术界, 2014,189(2):204-211.
|
|
Cheng Y . Analysis of abroad cross disciplinary research——From the perspective of academic journals[J]. Academics in China, 2014,189(2):204-211.
|

 )
)