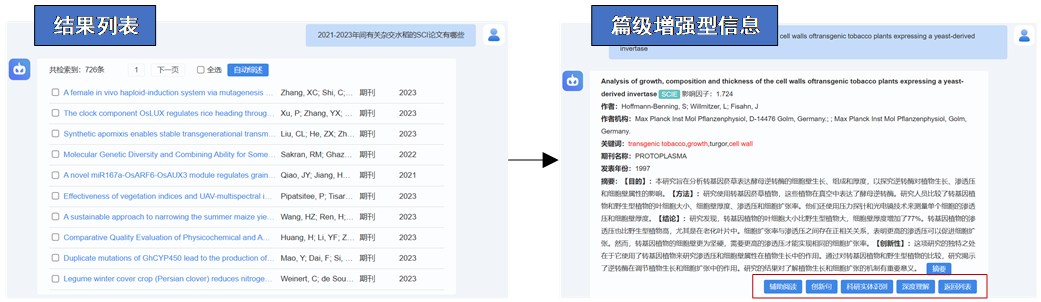
| [1] |
NERKAR G, DEVARUMATH S, PURANKAR M, et al. Advances in crop breeding through precision genome editing. Frontiers in Genetics, 2022, 13:1-14.https://doi.org/10.3389/fgene.2022.880195.
|
| [2] |
科技部, 教育部, 工业和信息化部, 等. 科技部等六部门印发《关于加快场景创新以人工智能高水平应用促进经济高质量发展的指导意见》[A]. 2022.
|
|
Ministry of Science and Technology, Ministry of Education, Ministry of Industry and Information Technology, et al. Notification from the Ministry of Science and Technology and five other departments on issuing the “Guidelines on accelerating scenario innovation to promote high-level AI application and high-quality economic development” [A]. 2022.
|
| [3] |
国家数据局. 国家数据局等部门关于印发《“数据要素×”三年行动计划(2024—2026年)》[A]. 2024.
|
|
National Data Bureau. Notification from the National Data Bureau and other departments on issuing the “Three-year action plan for data elements × (2024—2026)” [A]. 2024.
|
| [4] |
丁文家, 胡峻铭, 王嘉力. 水稻育种主要目标性状基因挖掘研究进展. 杂交水稻, 2023, 38(3): 1-19.
|
|
DING W J, HU J M, WANG J L. Research progress on gene mining of main target traits in rice breeding. Hybrid Rice, 2023, 38(3): 1-19.
|
| [5] |
SHU X, YE Y. Knowledge discovery: Methods from data mining and machine learning. Social Science Research, 2023, 110: 1-16.
|
| [6] |
李娇, 赵瑞雪, 鲜国建, 等. 论证挖掘研究现状与进展. 农业图书情报学报, 2023, 35(6): 16-28.
doi: 10.13998/j.cnki.issn1002-1248.23-0347
|
|
LI J, ZHAO R X, XIAN G J, et al. Research adcances in argument mining. Journal of Library and Information Science in Agriculture, 2023, 35(6): 16-28.
|
| [7] |
FOSTER J G, RZHETSKY A, EVANS J A. Tradition and innovation in scientists’ research strategies. American Sociological Review, 2015, 80(5): 875-908.
doi: 10.1177/0003122415601618
|
| [8] |
WYSOCKI O, CARVALHO D, BOGATU A, et al. An LLM-based knowledge synthesis and scientific reasoning framework for biomedical discovery//In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics(Volume 3: System Demonstrations), ACL, 2024: 355-364.
|
| [9] |
HUO C, HAN Y, HUO F, et al. An approach for interdisciplinary knowledge discovery: link prediction between topics. Physica A: Statistical Mechanics and Its Applications, 2025, 665: 1-14.
|
| [10] |
李文杰, 杨慧鑫, 胡丽, 等. 水稻中HSP20家族基因鉴定及表达[J/OL]. 应用与环境生物学报, 1-16 [2024-12-05]. https://doi.org/10.19675/j.cnki.1006-687x.2024.06033.
|
|
LI W, YANG H, HU L, et al. Identification and expression analysis of HSP20 family genes in Oryzasativa[J/OL]. Chinese Journal of Applied and Environmental Biology, 1-16 [2024-12-05].
|
| [11] |
QIU Z, MA F, LI Z, et al. Estimation of nitrogen nutrition index in rice from UAV RGB images coupled with machine learning algorithms. Computers and Electronics in Agriculture, 2021, 189: 1-9.
|
| [12] |
ZHANG D, ZHAO R, XIAN G, et al. A new model construction based on the knowledge graph for mining elite polyphenotype genes in crops. Frontiers in Plant Science, 2024, 15: 1-12.
|
| [13] |
曹雨晴, 鲜国建, 黄永文, 等. 全景式多路径知识图谱构建研究——以水稻粒型基因领域为. 数字图书馆论坛, 2022(4): 25-34.
|
|
CAO Y Q, XIAN G J, HUANG Y W, et al. Research on the construction of panorama domain knowledge graph: Using a case study of grain shape gene in rice. Digital Library Forum, 2022(4): 25-34.
|
| [14] |
MA X, WANG H, WU S, et al. DeepCCR: large-scale genomics-based deep learning method for improving rice breeding. Plant Biotechnology Journal, 2024, 22: 2691-2693.
doi: 10.1111/pbi.v22.10
|
| [15] |
BAI J, BAI S, CHU Y, et al. Qwen technical report. arXiv preprint, 2023, arXiv:2309.16609.
|
| [16] |
GUO D, YANG D, ZHANG H, et al. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning!. arXiv preprint arXiv:2501.12948,2025.
|
| [17] |
LI J, XIAN G, ZHAO R, et al. RDFAdaptor: Efficient ETL plugins for RDF data process. Journal of Data and Information Science, 2021, 6(3): 123-145.
doi: 10.2478/jdis-2021-0020
|
| [18] |
赵瑞雪, 杨潇, 李娇, 等. AI4S背景下的知识服务变革:模式演化与应对策略. 情报理论与实践, 2025, 48(4): 44-53.
|
|
ZHAO R, YANG X, LI J, et al. Knowledge service transformation in the context of AI for Science (AI4S): Model evolution and response strategies. Information Studies: Theory & Application, 2025, 48(4): 44-53.
|

 ), 鲜国建1,2,3, 黄永文1,2, 罗婷婷1,2, 孙坦3,4,*(
), 鲜国建1,2,3, 黄永文1,2, 罗婷婷1,2, 孙坦3,4,*(