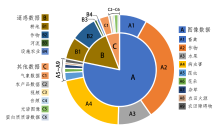
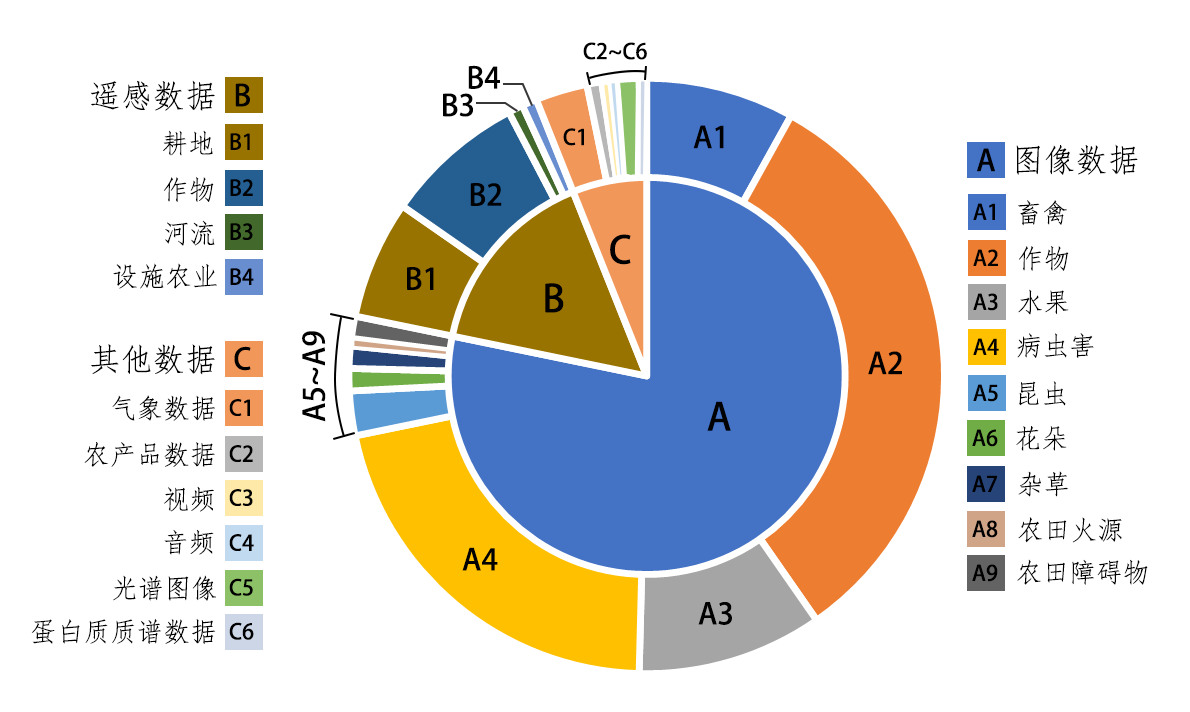
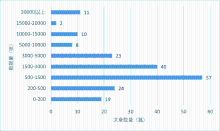
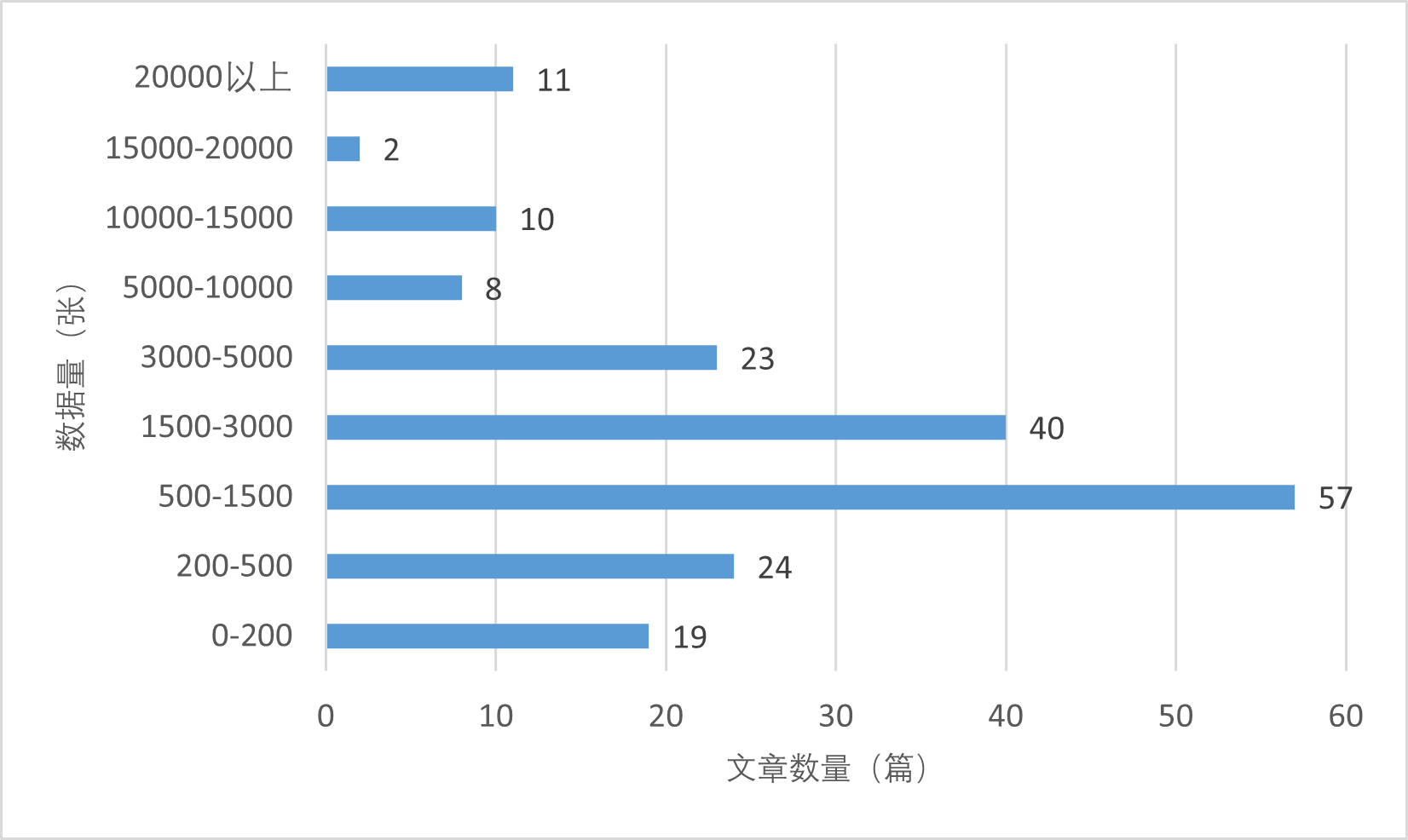
| [1] |
詹骐源. 机器学习的发展史及应用前景[J]. 科技传播, 2018, 10(21): 138-139.
|
| [2] |
徐清华, 郑誉煌, 戴冰燕. 基于深度残差网络的水果图像分类算法研究[J]. 工业控制计算机, 2020, 33(12):37-38+40.
|
| [3] |
彭顺正, 黄筑斌, 岳延滨. 基于深度学习的油菜籽粒图像分割方法初探[J]. 农技服务, 2020, 37(10):37-39.
|
| [4] |
LIU Y, LIU S, XU J, et al. Forest pest identification based on a new dataset and convolutional neural network model with enhancement strategy[J/OL]. Computers and Electronics in Agriculture, 2022, 192:106625. https://doi.org/10.1016/j.compag.2021.106625.
|
| [5] |
ATTRI I, AWASTHI L K, SHARMA T P, et al. A review of deep learning techniques used in agriculture[J/OL], Ecological Informatics, 2023, 77:102217. https://doi.org/10.1016/j.ecoinf.2023.102217.
|
| [6] |
ZHU Y, ABDALLA A, TANG Z. et al. Improving rice nitrogen stress diagnosis by denoising strips in hyperspectral images via deep learning[J]. Biosystems Engineering, 2022, 219:165-176. https://doi.org/10.1016/j.biosystemseng.2022.05.001.
|
| [7] |
XUAN G, GAO C, SHAO Y, et al. Apple detection in natural environment using deep learning algorithms[J]. IEEE Access, 2020, 216772-216780. https://doi.org/10.1109/ACCESS.2020.3040423.
|
| [8] |
孙烨, 董春雨. 复杂性视阈下的当代人工智能发展——以深度学习为例[J]. 系统科学学报, 2023, 31(4):13-22.
|
| [9] |
赵亚楠, 邓寒冰, 刘婷, 等. 基于弱监督学习的玉米苗期植株图像实例分割方法[J]. 农业工程学报, 2022, 38(19):143-152.
|
| [10] |
苏令涛, 李瑞泽, 张功磊, 等. 基于深度学习的农作物病虫害识别研究[J]. 数学建模及其应用, 2022, 11(4):1-12.
|
| [11] |
张庆辉, 张媛, 张梦雅. 有遮挡人脸识别进展综述[J]. 计算机应用研究, 2023, 40(8):2250-2257+2273.
|
| [12] |
马永建, 汪传建, 赵庆展, 等. 基于GF-1遥感影像的荒漠区耕地分类与提取方法[J]. 石河子大学学报(自然科学版), 2021, 39(3):383-390.
|
| [13] |
宋晓倩, 张学艺, 张春梅, 等. 基于深度迁移学习的酿酒葡萄种植信息提取[J]. 江苏农业学报, 2020, 36(3):689-693.
|
| [14] |
袁盼丽, 汪传建, 赵庆展, 等. 基于深度学习的寒旱区多时序影像土地利用及变化监测——以新疆莫索湾垦区为例[J]. 干旱区地理, 2021, 44(6):1717-1728.
doi: 10.12118/j.issn.1000–6060.2021.06.20
|
| [15] |
冯权泷, 陈泊安, 李国庆, 等. 遥感影像样本数据集研究综述[J]. 遥感学报, 2022, 26(4):589-605.
|
| [16] |
田地. 采用遗传算法优化的深度学习模型在育种中的实践[J]. 分子植物育种, 2024, 22(1):286-291.
|
| [17] |
尉震行. 目标识别算法综述[J]. 中国设备工程, 2019,(1):94-97.
|
| [18] |
黄雯珂, 滕飞, 王子丹, 等. 基于深度学习的图像分割综述[J]. 计算机科学, 2024, 51(2):107-116.
doi: 10.11896/jsjkx.230900002
|
| [19] |
向雁, 侯艳林, 姜文来, 等. LSTM模型在耕地面积预测领域的构建与应用[J]. 科技导报, 2021, 39(9):100-108.
doi: 10.3981/j.issn.1000-7857.2021.09.012
|
| [20] |
CORTEZ B, CARRERA B, KIM Y J, et al. An architecture for emergency event prediction using LSTM recurrent neural networks[J]. Expert Systems with Applications, 2018, 97: 315-324. https://doi.org/10.1016/j.eswa.2017.12.037
|
| [21] |
田鹏菲, 王皞阳. 机器视觉技术在我国农业领域内的应用分析[J]. 江苏农业科学, 2023, 51(14):13-21.
|
| [22] |
黄凯奇, 任伟强, 谭铁牛. 图像物体分类与检测算法综述[J]. 计算机学报, 2014, 37(6): 1225-1240.
|
| [23] |
HORAK K, SABLATNIG R. Deep learning concepts and datasets for image recognition: overview 2019[C]// Proceedings Volume 11179, Eleventh International Conference on Digital Image Processing (ICDIP 2019), 2019:111791S. https://doi.org/10.1117/12.2539806
|
| [24] |
孙书魁, 范菁, 孙中强, 等. 基于深度学习的图像数据增强研究综述[J/OL]. 计算机科学,1-23[2023-12-07].
|
| [25] |
ARSENOVIC M, KARANOVIC M, SLADOJEVIC S, et al. Solving current limitations of deep learning based approaches for plant disease detection[J]. Symmetry, 2019, 11(7): ID 939.
|
| [26] |
管博伦, 张立平, 朱静波, 等. 农业病虫害图像数据集现状及高质量构建综述[J]. 智慧农业, 2023, 5(3):17-34.
|

 ), 张建华1,2,3, 王健1,2,3, 周国民1,2,3,*(
), 张建华1,2,3, 王健1,2,3, 周国民1,2,3,*(