农业大数据学报 ›› 2025, Vol. 7 ›› Issue (2): 220-226.doi: 10.19788/j.issn.2096-6369.100051
张丹丹1,2( ), 赵瑞雪1,2,*(), 宼远涛1,2,*(), 鲜国建1,3
), 赵瑞雪1,2,*(), 宼远涛1,2,*(), 鲜国建1,3
ZHANG DanDan1,2(), ZHAO RuiXue1,2,*(), KOU YuanTao1,2,*(), XIAN GuoJian1,3
摘要:
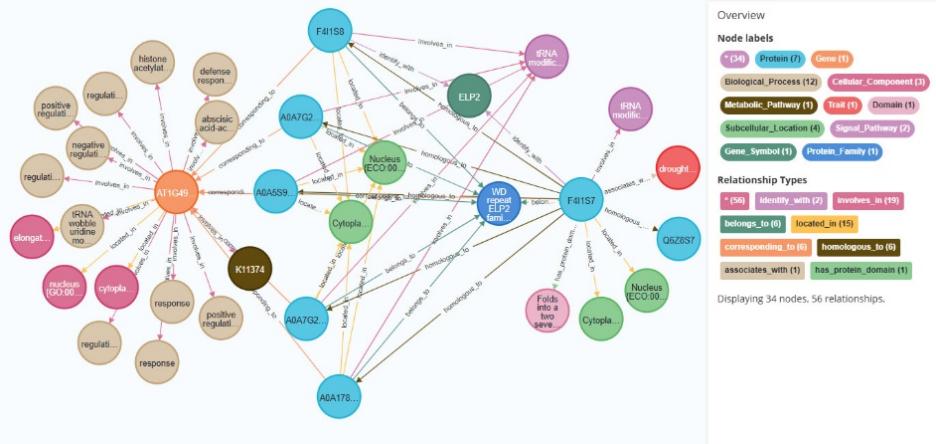
当前,作物育种相关的多维度科学数据呈指数级增长,这些半结构化和结构化的科学数据分布在不同领域科学数据库中,缺少跨物种多维度科学数据的关联融合数据集,阻碍了已有作物育种知识的迁移复用与作物育种科学数据价值的最大化发挥,这为作物性状调控基因知识发现带来了挑战。本研究基于数据的可靠性、实用性、易用性等原则,选取PubMed文献数据库与Phytozome、Ensembl plants、UniProt、RGAP、STRING、Pfam、KEGG和GO作为数据获取来源,采用多路径知识抽取的方式对不同数据格式的科学数据分别进行实体及关系的抽取。面向结构化数据的映射知识抽取;面向XML半结构化数据,采用基于Kettle进行数据解析的知识抽取;面向FASTA半结构化数据,采用基于BLAST模型计算的知识抽取。面向Text非结构化数据,采用基于大语言模型的知识抽取。在完成以上实体和关系抽取的基础上,进一步基于实体映射和特定属性关联的方式,实现多源作物育种知识的关联融合。形成了作物性状调控基因知识图谱数据集,并以.csv格式存储为结构化数据。该数据集包含13个实体数据集和14个语义关系数据集。为了验证该数据集的有效性,采用Neo4j图数据库进行数据集存储。最终,形成了涵盖约13万个节点和55万条语义关系的作物性状调控基因知识图谱,可有效支撑跨物种基因知识的关联检索。作物性状调控基因知识图谱数据集已为优异多效基因发现、跨物种基因功能预测与通路基因网络潜在发现等作物育种知识发现提供了关键的语义模型和重要的数据基础。相关科研和生产单位可基于本数据集构建作物性状调控基因知识库,为作物育种知识发现服务平台的构建提供关键的知识资源底座。
数据摘要:
| 项目 | 描述 |
|---|---|
| 数据集名称 | 作物性状调控基因知识图谱数据集 |
| 所属学科 | 农学其他学科(21099) |
| 研究主题 | 作物;性状调控基因知识图谱;数据挖掘 |
| 数据类型与技术格式 | .csv |
| 数据库(集)组成 | 27个表格文件,包含水稻、玉米、小麦、拟南芥跨物种关联融合的13个实体数据集与14个语义关系数据集。 |
| 数据量 | 32.18 MB |
| 主要数据指标 | 转录组名称、功能描述、物理位置、物种等 |
| 数据可用性 | CSTR: 17058.11.sciencedb.agriculture.00175; https://cstr.cn/17058.11.sciencedb.agriculture.00175 DOI: 10.57760/sciencedb.agriculture.00175; |
| 经费支持 | 中国农业科学院科技创新工程(CAAS-ASTIP-2016-AII) |